
In this article, we will perform the derivation of Bellman equation for both state-value and action-value functions. Then, we will go through a simple Grid World example on using Bellman equation to obtain the value of each state.
The State-Value Function
A state-value function describes the expected return of the agent for a given state $s$ following a given policy, $\pi$. The state-value function is denoted by $v_{\pi}(s)$ is defined as follows.
\[v_{\pi}(s) \doteq \mathbb{E}_{\pi} \left[ G_t | S_t = s \right] \label{eq:sv_ori}\]where
- $\pi$: a given policy applied by the agent to interact with the environment,
- $s$: current state on the environment, and
- $G_t$: the return, which is the sum over the future rewards.
Note that $G_t$ is a random variable, therefore the state-value function is defined as the expected return of the agent for a given state $s$.
Bellman Equation: State-Value Function
The Bellman equation for the state-value function is defined as follows.
\[v_{\pi}(s) \doteq \sum_{a} \pi(a|s) \sum_{s'} \sum_{r} p(s', r | s, a) \left[ r + \gamma v_{\pi} (s') \right] \label{eq:sv_bellman}\]Notice how the state-value function for the current state $v_{\pi}(s)$ can be expressed as a recursive function with respect to the state-value function for the next state $v_{\pi}(s’)$.
The Action-Value Function
An action-value function describes what happens when the agent selects the particular action $a$ during the state $s$, and then follow the policy $\pi$. The action-value function, denoted by $q_{\pi}(s, a)$ is defined as follows.
\[q_{\pi}(s, a) \doteq \mathbb{E}_{\pi} \left[ G_t | S_t = s , A_t = a\right] \label{eq:av_ori}\]where
- $\pi$: a given policy applied by the agent to interact with the environment,
- $s$: current state on the environment,
- $a$: the selection action for current state $s$, and
- $G_t$: the return, which is the sum over the future rewards.
Bellman Equation: Action-Value Function
Similarly, the action-value function is defined as the expected return of the agent for selected action $a$ and given state $s$.
The Bellman equation for the action-value function is defined as follows.
\[q_{\pi}(s, a) \doteq \sum_{s'} \sum_{r} p(s', r | s, a) \left[ r + \gamma \sum_{a'} \pi(a'|s') q_{\pi} (s', a') \right] \label{eq:av_bellman}\]Notice how the action-value function for the current state and action $q_{\pi}(s, a)$ can also be expressed as a recursive function with respect to the action-value function for the next state $q_{\pi}(s’, a’)$.
You might be wondering…
How to convert the value functions into Bellman equation?
Before showing how to derive the Bellman equation for the value functions, it is important to know that, the state-value function $v_{\pi}(s)$ in can be expressed in terms of the action-value function $q_{\pi}(s,a)$, and vice versa.
Rewriting Value Functions
At this point, you might ask, why do we need to rewrite the value functions? Why do we care about all these? It might not make any sense for now, but don’t worry, you will know how it can help us to derive the Bellman equation for the value functions.
Rewriting $v_{\pi}(s)$ in Terms of $q_{\pi}(s,a)$
We start from $\eqref{eq:sv_ori}$:
\[\begin{align} v_{\pi}(s) &\doteq \mathbb{E}_{\pi} \left[ G_t | S_t = s \right] \\ &= \mathbb{E}_{\pi} \left[ \mathbb{E}_{\pi} \left[ G_t | S_t = s \right] | A_t = a \right] \\ &= \sum_a \pi(a|s) \mathbb{E}_{\pi} \left[ G_t | S_t = s, A_t = a \right] \\ &= \sum_a \pi(a|s) q_{\pi}(s,a) \label{eq:sv_in_av} \end{align}\]Rewriting $q_{\pi}(s,a)$ in Terms of $v_{\pi}(s)$
Recall that $G_t$ is the sum of future rewards, i.e.
\[\begin{align} G_t &= \sum_{k=0}^{\infty} \gamma^k R_{k+t+1} \notag \\ &= R_{t+1} + \gamma \sum_{k=1}^{\infty} \gamma^k R_{k+t+1} \notag \\ &= R_{t+1} + \gamma G_{t+1} \label{eq:return} \end{align}\]where $\gamma$ is the discounted value and $R_t$ is the reward at time $t$.
Therefore, we can substitute $\eqref{eq:return}$ into $\eqref{eq:av_ori}$, as follows:
\[\begin{align} q_{\pi}(s,a) &\doteq \mathbb{E}_{\pi} \left[ G_t | S_t = s, A_t = a \right] \\ &= \mathbb{E}_{\pi} \left[ R_{t+1} + \gamma G_{t+1} | S_t = s, A_t = a \right] \\ &= \mathbb{E}_{\pi} \left[ \mathbb{E}_{\pi} \left[ R_{t+1} + \gamma G_{t+1} | S_t = s, A_t = a \right] | R_t = r, S_{t+1} = s' \right] \\ &= \sum_{s'} \sum_{r} p(s',r|s,a) \mathbb{E}_{\pi} \left[ R_{t+1} + \gamma G_{t+1} | S_t = s, A_t = a, R_t = r, S_{t+1} = s' \right] \\ &= \sum_{s'} \sum_{r} p(s',r|s,a) \mathbb{E}_{\pi} \left[ R_{t+1} + \gamma G_{t+1} | S_{t+1} = s' \right] \label{eq:av_in_sv_1} \\ &= \sum_{s'} \sum_{r} p(s',r|s,a) \left[ r' + \gamma v_{\pi}(s') \right] \label{eq:av_in_sv_2} \end{align}\]Note that in $\eqref{eq:av_in_sv_1}$, both $R_{t+1}$ and $G_{t+1}$ are no longer dependent on current state $s$, current action $a$ and the immediate reward $r$. Therefore, these terms in the expectation are omitted.
In the next section, you will see the power of rewriting these value functions in helping us to derive Bellman equation for these value functions.
Deriving Bellman Equations
Recall $\eqref{eq:sv_in_av}$
\[v_{\pi}(s) \doteq \sum_a \pi(a|s) q_{\pi}(s,a) \notag\]and $\eqref{eq:av_in_sv_2}$
\[q_{\pi}(s,a) \doteq \sum_{s'} \sum_{r} p(s',r|s,a) \left[ r' + \gamma v_{\pi}(s') \right] \notag\]from earlier sections. To derive Bellman equation for state-value function, we substitute $\eqref{eq:av_in_sv_2}$ into $\eqref{eq:sv_in_av}$.
\[\begin{align} v_{\pi}(s) &\doteq \sum_a \pi(a|s) q_{\pi}(s,a) \notag \\ &= \sum_a \pi(a|s) \sum_{s'} \sum_{r} p(s',r|s,a) \left[ r' + \gamma v_{\pi}(s') \right] \end{align}\]We obtain the same equation as $\eqref{eq:sv_bellman}$, using only two lines.
Similarly, to derive Bellman equation for action-value function, we substitute $\eqref{eq:sv_in_av}$ into $\eqref{eq:av_in_sv_2}$.
\[\begin{align} q_{\pi}(s,a) &\doteq \sum_{s'} \sum_{r} p(s',r|s,a) \left[ r' + \gamma v_{\pi}(s') \right] \notag \\ &= \sum_{s'} \sum_{r} p(s',r|s,a) \left[ r' + \gamma \sum_{a'} \pi(a'|s') q_{\pi}(s',a') \right] \end{align}\]Note that we need to change $s$ and $a$ in $\eqref{eq:sv_in_av}$ to $s’$ and $a’$ respectively. This is because we want to replace the value of $v_{\pi}(s’)$, instead of $v_{\pi}(s)$.
We obtain the Bellman equation for action-value function similar to $\eqref{eq:av_bellman}$, as well.
Now, you see how powerful is the rewritten form of value functions in helping us to derive the Bellman equations for the respective value functions. Interesting, no?
Example: Grid World
To show the application of Bellman equation to simplify the calculation of value functions, let us consider the following Grid World example.
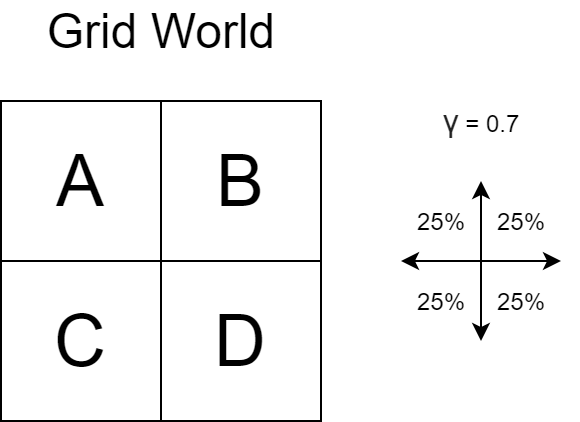
More details on the Grid World example:
- States: There are possible states, namely A, B, C and D.
- Actions: At each state, there are four possible actions: moving up, down, left and right.
- The new state depends on the action taken by the agent - for example: moving left from B brings the agent to A.
- If the agent hits the wall (e.g.: moving up/right from B), the agent bounds back to the same grid, i.e., the state remains unchanged. This is also applied to other states.
- Reward: When the new state is B, the reward is +5 (this includes moving up/right from B such that state remains unchanged). Otherwise, the reward is 0.
- Policy: The policy is stochastic, meaning each action performed on each state is assigned a certain probability. In this case, the actions are equiprobable (each having probability of 25%).
- Discount factor: $\gamma = 0.7$
After defining the problem, we need to find the value of each state, using Bellman equation defined from earlier sections.
First, we define the value of state A: $v_{\pi}(A)$, as follows:
\[v_{\pi}(A) = \sum_a \pi(a|A) \left(r + 0.7 v_{\pi}(A) \right) \label{eq:vA_pre}\]In this case, there is only one associated next state $s’$ and reward $r$ for each action $a$. Therefore, the double sum and the transition function $p(s’, r \vert s, a)$ in $\eqref{eq:sv_bellman}$ is omitted (because $p(s’, r \vert s, a) = 1$).
We expand the summation in $\eqref{eq:vA_pre}$:
\[v_{\pi}(A) = \frac{1}{2} \times \left(0.7 v_{\pi}(A) \right) + \frac{1}{4} \times \left(5 + 0.7 v_{\pi}(B) \right) + \frac{1}{4} \times \left(0.7 v_{\pi}(C) \right) \label{eq:vA}\]Next, we define the value for the other states, namely $v_{\pi}(B)$, $v_{\pi}(C)$ and $v_{\pi}(D)$, as follows:
\[\begin{align} v_{\pi}(B) &= \frac{1}{4} \times 0.7 v_{\pi}(A) + \frac{1}{2} \times \left(5 + 0.7 v_{\pi}(B) \right) + \frac{1}{4} \times 0.7 v_{\pi}(D) \label{eq:vB} \\ v_{\pi}(C) &= \frac{1}{4} \times 0.7 v_{\pi}(A) + \frac{1}{2} \times 0.7 v_{\pi}(C) + \frac{1}{4} \times 0.7 v_{\pi}(D) \label{eq:vC} \\ v_{\pi}(D) &= \frac{1}{4} \times \left(5 + 0.7 v_{\pi}(B) \right) + \frac{1}{4} \times 0.7 v_{\pi}(C) + \frac{1}{2} \times 0.7 v_{\pi}(D) \label{eq:vD} \end{align}\]Notice that the four equations of the value functions form a system of linear equations, which can be solved by using a system of equation solver. The values of each state are, respectively:
\[\begin{align} v_{\pi}(A) &= 4.2 \notag \\ v_{\pi}(B) &= 6.1 \notag \\ v_{\pi}(C) &= 2.2 \notag \\ v_{\pi}(D) &= 4.2 \notag \end{align}\]From the Grid World example, we learn that the Bellman equation can be powerful in helping us to find the values of each state in a Markov Decision Process.
References
- R. S. Sutton and A. G. Barto, Reinforcement learning: an introduction. Cambridge, MA: The MIT Press, 2018.